AI accent guesser technology is rapidly evolving, offering exciting possibilities while raising significant ethical concerns. This exploration delves into the algorithms powering these systems, examining their accuracy, efficiency, and the biases inherent in their training data. We will also consider the societal impact and potential for misuse, exploring applications and future developments in this fascinating field.
From the core machine learning models employed – including neural networks and support vector machines – to the challenges of accurately identifying accents across diverse linguistic backgrounds, we’ll examine the technological underpinnings and their limitations. The need for responsible data collection and mitigation of bias will be central to our discussion, highlighting the ethical considerations crucial for the deployment of this powerful technology.
AI Accent Guessers: Functionality, Ethics, and Future
AI accent guessers, systems capable of identifying a speaker’s accent based on their voice, are rapidly evolving. This technology leverages sophisticated algorithms and machine learning to analyze acoustic features of speech, offering a range of applications across various fields. However, alongside its potential benefits, the ethical implications and potential for bias require careful consideration.
AI Accent Guesser Technology
AI accent identification relies on analyzing various acoustic characteristics of speech. The core algorithms employ machine learning models to identify patterns in these features that correlate with specific accents.
Several machine learning models are used, including deep neural networks (DNNs), which excel at complex pattern recognition, and support vector machines (SVMs), known for their efficiency in high-dimensional data. DNNs generally offer higher accuracy but often require significantly more computational resources and data for training. SVMs, while potentially less accurate, can be more efficient for smaller datasets.
AI accent guessers are fascinating tools, capable of identifying subtle nuances in speech. Consider the complexities involved; imagine an AI trying to differentiate accents amidst the chaos of a natural disaster, like the recent earthquake in Vanuatu, as reported here: Vanuatu hit by another earthquake as hundreds of Australians return. The varied accents of those affected, and those providing aid, would present a unique challenge for even the most advanced AI accent guesser.
Further research into such technology could improve disaster response capabilities.
The accuracy and efficiency of different approaches vary depending on factors such as the size and quality of the training data, the complexity of the model, and the specific accents being identified. Generally, DNNs, especially those utilizing recurrent neural networks (RNNs) or convolutional neural networks (CNNs) for sequential and spectral feature analysis, outperform SVMs in accuracy but come with a higher computational cost.
| Algorithm | Accuracy Rate | Processing Speed | Data Requirements |
|---|---|---|---|
| Deep Neural Networks (DNNs) | High (e.g., 85-95% depending on dataset and accent) | Relatively Slow | Large, diverse, and high-quality datasets |
| Support Vector Machines (SVMs) | Moderate (e.g., 70-85%) | Relatively Fast | Smaller datasets can be sufficient |
| Hidden Markov Models (HMMs) | Moderate (e.g., 65-80%) | Fast | Moderate dataset size |
Data Requirements and Bias Mitigation, Ai accent guesser
Training effective AI accent guessers requires substantial amounts of high-quality audio data representing a wide range of accents and speakers. The quantity needed depends heavily on the number of accents targeted and the desired accuracy. Millions of labelled audio samples are often necessary for robust performance.
However, biases in training data pose a significant challenge. Overrepresentation of certain accents or underrepresentation of others can lead to inaccurate or unfair predictions. For instance, a model trained primarily on data from North American English might struggle to accurately identify accents from other regions.
AI accent guessers are fascinating tools, capable of identifying subtle nuances in speech. Their accuracy, however, can vary widely depending on the dataset used for training; for example, consider the diverse accents likely present amongst the fans at the Montana State Bobcat game, as detailed in BOBCAT GAME DAY NOTEBOOK #15: Montana State Plays Final. The sheer variety of voices would present a significant challenge for even the most advanced AI accent guesser.
To mitigate bias, careful attention must be paid to data collection. This includes ensuring balanced representation of diverse accents, using diverse recording environments, and implementing rigorous data cleaning and pre-processing techniques. Techniques like data augmentation (creating variations of existing data) can help address imbalances. Regular model evaluation with diverse test sets can also help identify and correct biases.
Biases can manifest as misclassifications, with accents from underrepresented groups being incorrectly identified or grouped together. For example, a biased model might consistently misclassify various Indian accents as a single generic “Indian accent,” failing to distinguish between the nuances of different regional variations.
Ethical Considerations and Societal Impact

The potential for misuse of AI accent guessers is a critical ethical concern. These systems could be used for discriminatory purposes, such as profiling individuals based on their accent or unfairly targeting specific groups in areas like hiring or loan applications.
Furthermore, the collection and analysis of voice data raise significant privacy concerns. Ensuring data security and obtaining informed consent are crucial to protect individual privacy.
- Prioritize data privacy and security.
- Obtain informed consent from all participants.
- Ensure transparency in data usage and model development.
- Implement robust bias mitigation strategies.
- Regularly audit and evaluate the system for bias and fairness.
- Promote responsible innovation and deployment.
Transparency and accountability are vital. Developers should clearly document the data used, the algorithms employed, and the system’s limitations. Regular audits and independent evaluations can help ensure fairness and prevent unintended consequences.
Applications and Future Advancements
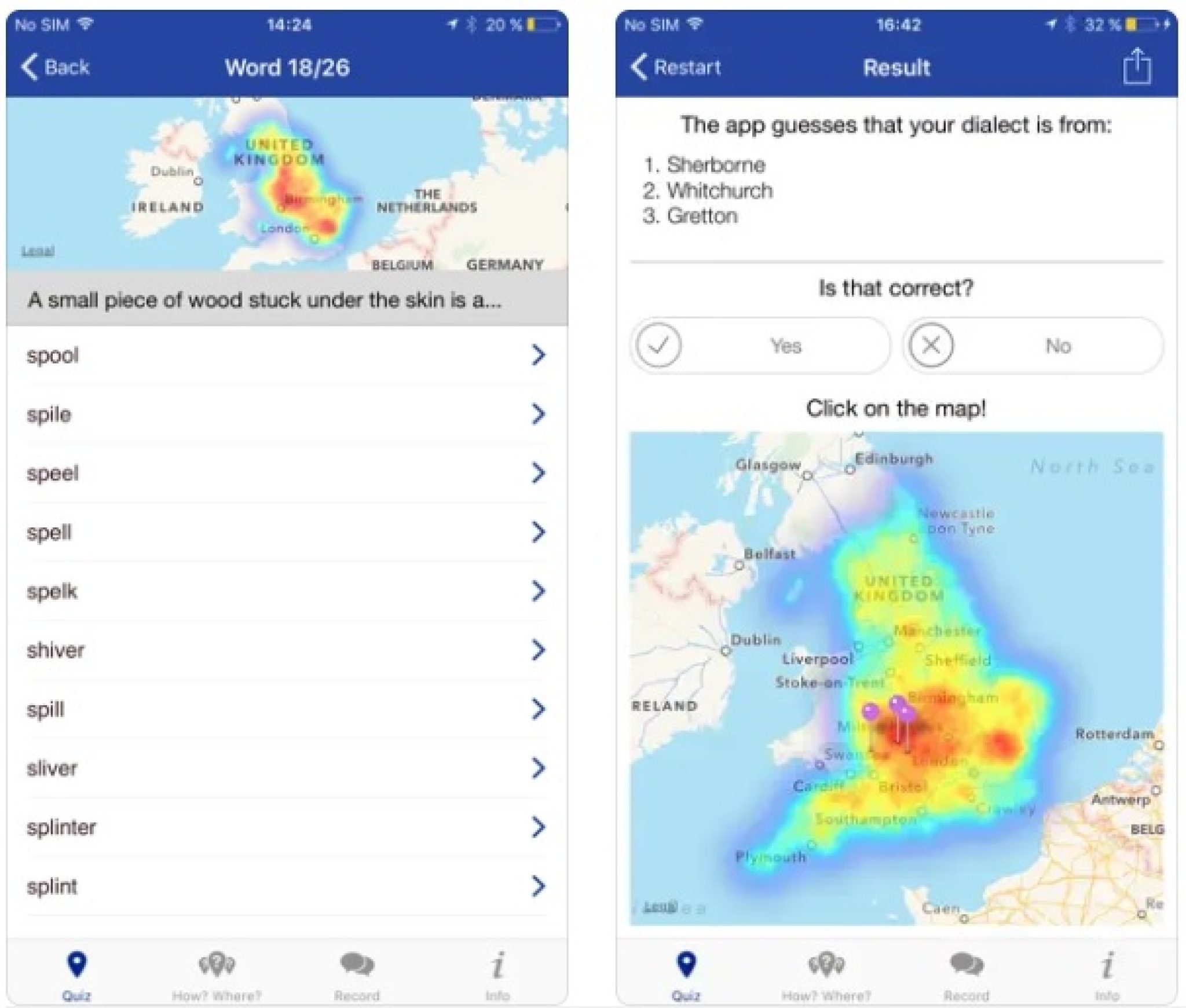
AI accent guessers have several practical applications. In language learning, they can provide personalized feedback on pronunciation. In accessibility tools, they can aid individuals with speech impairments. Customer service applications can leverage them to personalize interactions and improve service quality.
Future advancements might include real-time processing with improved accuracy and the ability to identify a wider range of accents. Research focuses on incorporating linguistic features beyond purely acoustic ones to enhance accuracy. The challenges lie in addressing the diversity of global languages and accents, each with unique phonetic and prosodic characteristics.
Current limitations include the difficulty in distinguishing between subtle accent variations and the impact of background noise or speaker characteristics on accuracy. Future development will likely focus on more robust models that can handle noisy environments and incorporate speaker-specific features to improve performance.
Illustrative Example of Accent Recognition
An AI accent guesser processes an audio clip through several stages. First, the audio is pre-processed to remove noise and normalize the volume. Next, acoustic features are extracted, including fundamental frequency (pitch), intensity (loudness), spectral features (formants), and temporal features (rhythm and pauses).
These features are then fed into a machine learning model, which identifies patterns associated with different accents. For example, a high-pitched voice with rapid speech might be associated with a certain accent, while a low-pitched voice with distinct intonation patterns might indicate another. The model compares these extracted features against its training data and assigns a probability to each accent in its database.
The accent with the highest probability is identified as the likely accent of the speaker.
Consider the acoustic features: A speaker with a strong Southern US accent might exhibit a characteristic drawl, reflected in elongated vowels and a slower tempo. This contrasts with a speaker from the Northeast US, who might exhibit a faster tempo and a different intonation pattern.
Visual Representation (Text-based):
Accent A (e.g., Southern US): Pitch: Relatively low; Intonation: Relatively flat; Rhythm: Slow; Vowel Length: Long
Accent B (e.g., Northeastern US): Pitch: Moderate; Intonation: More varied; Rhythm: Fast; Vowel Length: Short
AI accent guessers present a double-edged sword: a powerful tool with the potential for significant benefits in various fields, yet fraught with ethical complexities. Addressing biases in training data, ensuring user privacy, and promoting transparency are crucial for responsible development and deployment. The future of this technology hinges on a commitment to ethical guidelines and a mindful approach to its applications, maximizing its positive impact while mitigating potential harm.
FAQ Explained: Ai Accent Guesser
How accurate are AI accent guessers?
Accuracy varies significantly depending on the algorithm, training data, and the specific accents involved. While advancements are being made, perfect accuracy remains elusive.
Can AI accent guessers identify all accents?
No, current AI accent guessers struggle with less-represented languages and dialects. The accuracy diminishes considerably when dealing with accents not adequately represented in the training data.
What are the privacy implications of using AI accent guessers?
Using AI accent guessers involves collecting and analyzing voice data, raising concerns about data security and potential misuse. Strong privacy protections are essential.